
はじめに
近年、ChatGPTをはじめとする生成AIの進化は目覚ましく、多くの企業で業務効率化や新たなサービス創出のための活用が期待されています。しかしその一方で、生成AIが事実に基づかない情報を生成する「ハルシネーション」の発生や、学習データが古いために最新の情報に答えられないといった課題の存在も明確となってきました。
このような課題を解決する技術として、今注目を集めているのが「RAG(Retrieval-Augmented Generation:検索拡張生成)」です。この記事では、RAGの基本的な仕組みからメリット、具体的な活用事例までを分かりやすく解説します。
RAG(検索拡張生成)とは?生成AIの精度を高める技術

RAG(ラグ)とは、「Retrieval-Augmented Generation」の略称で、日本語では「検索拡張生成」と訳されます。これは、大規模言語モデル(LLM)が持つ一般的な知識に加えて、外部の信頼できる情報源から関連データを検索し、その情報を基に回答を生成する技術です。
従来の生成AIは、事前に学習した膨大なデータの中だけで回答を生成していました。それに対しRAGは、ユーザーから質問を受けるたびに、社内文書やデータベースといった専門的な情報源を参照します。これにより、生成AIの弱点であった情報の不正確さや古さを補い、より信頼性の高い回答を生み出すことが可能になります。
なぜ今RAGが注目されるのか?LLMが抱える3つの課題
生成AI、特にその中核をなすLLM(大規模言語モデル)は非常に強力ですが、ビジネスで本格的に活用するにはいくつかの課題が存在します。
RAGは、これらの課題に対する有効な解決策として注目されています。
| 課題の種類 | 具体的な内容 | RAGによる解決策 |
| ハルシネーション | 事実に基づかない、 もっともらしい嘘の情報を 生成してしまう。 |
回答生成時に信頼できる情報源を 根拠として参照させることで、 誤った情報の生成を抑制する。 |
| 情報の鮮度 | 学習データが特定の時点 までのものに限定され、 最新の出来事や情報に対応できない。 |
リアルタイムで更新されるデータベースや 文書を検索対象とすることで、 常に最新の情報に基づいた回答が可能になる。 |
| 専門知識の不足 | 社内の独自ルールや専門用語、 非公開情報など、特定の分野に 特化した知識を持たない。 |
社内規定やマニュアル、 製品仕様書などを検索対象とすることで、 組織独自の専門的な質問にも 正確に答えられるようになる。 |
【課題1】平気で嘘をつく「ハルシネーション」
LLMは、確率的にもっともらしい単語の連なりを生成する仕組みのため、事実と異なる内容をあたかも真実であるかのように回答してしまうことがあります。これを「ハルシネーション(幻覚)」と呼びます。ビジネスの意思決定や顧客対応など、正確性が求められる場面でハルシネーションが発生すると、大きな問題につながる可能性があります。RAGは、回答の根拠となる情報を外部から提供することで、このリスクを大幅に低減します。
【課題2】学習データが古く、最新情報に答えられない
多くのLLMは、ある特定の時点までに収集されたデータセットで学習しています。そのため、学習データに含まれていない最新のニュースや法改正、市場の動向などに関する質問には答えることができません。一方でRAGは、外部データベースの情報を都度参照するため、該当のデータベースを適切に更新・メンテナンスすることで、回答として提供される知識の鮮度を保つことができます。
【課題3】社内情報など専門的な知識を持たない
一般的なLLMはインターネット上の広範な知識を持っていますが、特定の企業や業界だけで使われる専門用語、社内ルール、非公開の製品情報といったクローズドな知識は持っていません。RAGを活用すれば、社内のファイルサーバーやナレッジベースをLLMに連携させ、組織の「専属アシスタント」として機能させることが可能となります。
RAGの仕組みを3ステップでわかりやすく解説
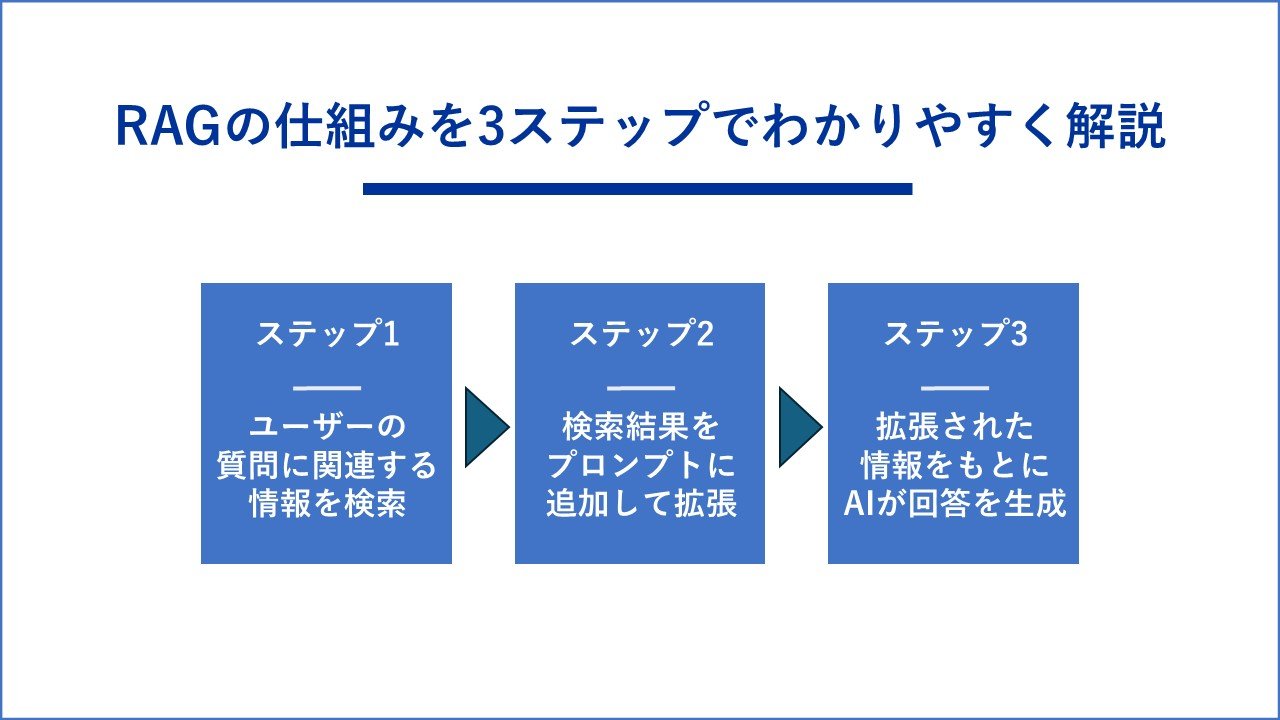
RAGは、どのようにしてLLMの回答精度を高めているのでしょうか。
その仕組みは、大きく分けて「検索」「拡張」「生成」の3つのステップで構成されています。
【ステップ1】ユーザーの質問に関連する情報を検索
まず、ユーザーが質問を入力すると、RAGシステムはその質問内容を解析します。そして、あらかじめ準備された企業の文書やFAQ、データベースといった知識源の中から、質問と関連性の高い情報を検索(Retrieval)して見つけ出します。この検索の精度が、最終的な回答の品質を大きく左右する重要なポイントとなります。
【ステップ2】検索結果をプロンプトに追加して拡張
次に、ステップ1で検索して見つけた関連情報を、ユーザーが入力した元の質問(プロンプト)に付加します。これにより、LLMに与える指示が「ユーザーの質問」と「回答の根拠となる参考情報」を組み合わせた、より具体的で情報豊富なものに拡張(Augmented)されます。
【ステップ3】拡張された情報をもとにAIが回答を生成
最後に、拡張されたプロンプトをLLMに渡します。LLMは、与えられた参考情報に基づいて、ユーザーの質問に対する回答を生成(Generation)します。これにより、LLMが元々持っている一般的な知識だけでなく、外部の正確な情報も加味された、信頼性の高い回答が作成されるのです。
RAGを導入する4つのメリット
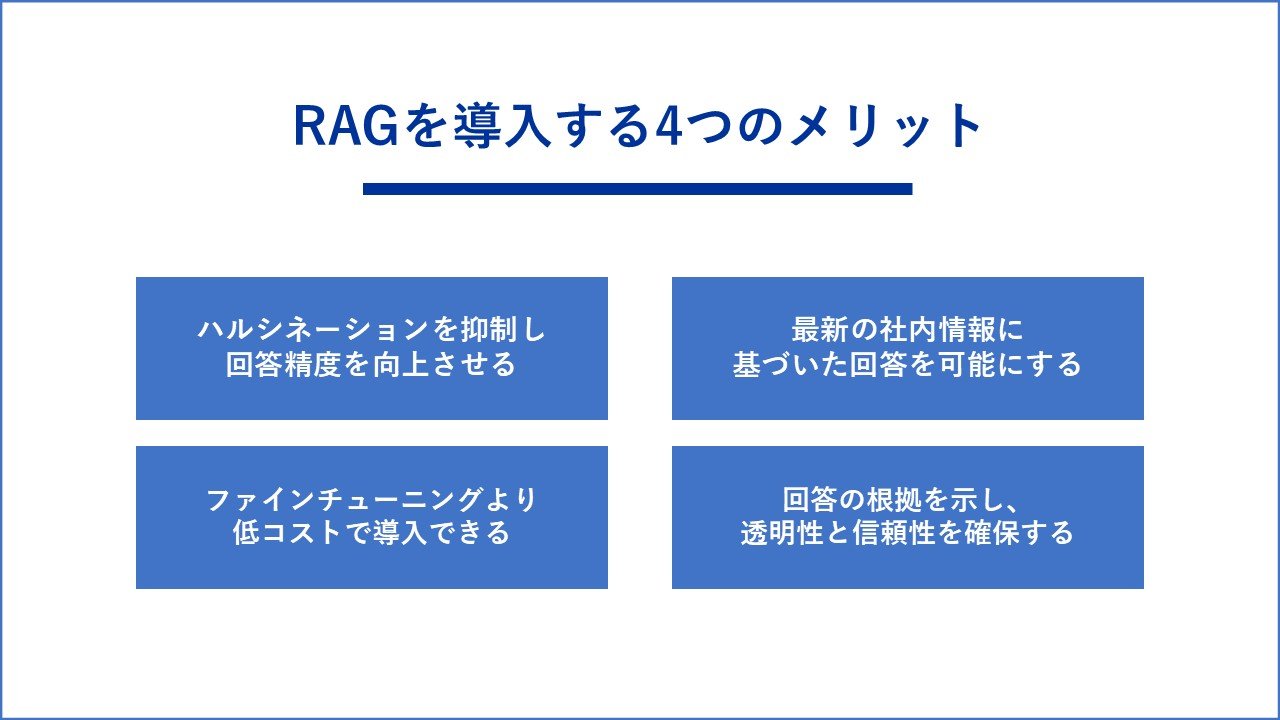
RAGを導入することは、企業に多くのメリットをもたらします。
特に「回答精度の向上」「最新情報への対応」「コスト効率」「透明性」の4つの観点で大きな効果が期待できます。
【メリット1】ハルシネーションを抑制し回答精度を向上させる
最大のメリットは、生成AIの回答精度が飛躍的に向上することです。信頼できる社内データなどを根拠として回答を生成するため、LLMが不確かな知識だけで応答するのを防ぎ、ハルシネーションのリスクを大幅に低減できます。これにより、顧客対応や業務判断など、正確性が不可欠な業務でも安心して生成AIを活用できます。
【メリット2】最新の社内情報に基づいた回答を可能にする
社内規定やマニュアル、日報といった情報は頻繁に更新されます。RAGは、これらの最新ドキュメントを直接参照できるため、常に現状に即した回答を生成できます。社員が古い情報に基づいて誤った判断をすることを防ぎ、組織全体の業務品質を向上させます。
【メリット3】ファインチューニングより低コストで導入できる
LLMに専門知識を学習させるもう一つの方法として「ファインチューニング」がありますが、これには大量の学習データと高い計算コストが必要です。一方、RAGは既存のドキュメントをデータベース化するだけで済むため、比較的低コストかつ短期間で専門的な知識に対応したAIシステムを構築できます。
【メリット4】回答の根拠を示し、透明性と信頼性を確保する
RAGは、AIがどの文書のどの部分を参考にして回答を生成したのか、その出典を明示することができます。これにより、ユーザーは回答の正しさを自ら確認でき、AIの応答に対する信頼性が高まります。万が一回答が誤っていた場合でも、原因の特定と修正が容易になります。
RAGのデメリットと導入時の注意点

多くのメリットがあるRAGですが、導入にあたってはいくつかのデメリットや注意点も存在します。
これらを事前に理解し、対策を講じることが成功の鍵となります。
【デメリット1】検索システムの精度が回答品質を左右する
RAGの性能は、ステップ1の「情報検索」の精度に大きく依存します。ユーザーの質問に対して適切で過不足のない情報を検索できなければ、後続のLLMも質の高い回答を生成できません。したがって、意図に沿った情報を的確に見つけ出す、高性能な検索エンジンの導入が不可欠です。
【デメリット2】適切な知識データベースの構築が必要になる
RAGに参照させる知識データベースの品質管理も重要です。情報が古かったり、誤った情報が含まれていたりすると、AIもそれに倣った不正確な回答を生成してしまいます。誰が、いつ、どのように情報を更新し、その品質を維持していくのか、運用体制をあらかじめ設計しておく必要があります。
RAGとファインチューニングの違いとは?
LLMを特定の業務に特化させる手法として、RAGとしばしば比較されるのが「ファインチューニング」です。両者は目的が似ていますが、そのアプローチは大きく異なります。用途に応じて適切な手法を選択することが重要です。
| 比較項目 | RAG(検索拡張生成) | ファインチューニング |
| アプローチ | 外部の知識を都度検索して参照する | モデル自体に追加のデータセットを学習させる |
| 知識の更新 | データベースの情報を更新するだけで容易に行える | モデルの再学習が必要で、時間とコストがかかる |
| コスト | 比較的低コスト | 高い計算コストと専門知識が必要 |
| 得意なこと | 最新情報や事実に基づく正確な回答、根拠の提示 | モデルの口調や応答スタイル、振る舞いの調整 |
| 適した用途 | 社内規定の検索、FAQ、最新情報に基づくレポート作成 | 特定のキャラクターを持った専門性に特化したAI |
知識の更新方法と範囲の違い
RAGは、外部データベースの情報を更新するだけで、AIが参照する知識を最新の状態に保てます。一方、ファインチューニングはモデル自体を再学習させる必要があり、手間とコストがかかります。頻繁に情報が更新される業務にはRAGが適しています。
コストと実装期間の違い
一般的に、RAGはファインチューニングに比べて低コストかつ短期間で実装が可能です。ファインチューニングには、質の高い大量の学習データペアの準備と、モデルを学習させるための高度な技術力や計算リソースが求められます。
回答の柔軟性と専門性の違い
RAGは事実に基づいた回答を得意としますが、AIの口調や応答スタイルを細かく調整するのは苦手です。対してファインチューニングは、特定の文体や専門的な対話スタイルをモデルに学習させることが得意です。企業のブランドイメージに沿った対話AIを開発する場合などは、ファインチューニングが有効な選択肢となります。
RAGの代表的な活用事例

RAGは、その特性を活かして様々なビジネスシーンで活用され始めています。ここでは、代表的な活用事例を紹介します。
【事例1】LINEヤフー株式会社
LINEヤフー(株)では、RAG技術を活用した独自業務効率化ツール「SeekAI」を全従業員に導入しています。SeekAIは、膨大な社内文書データベースから検索要件に最適化された情報を取得し、回答を生成する自然言語処理技術であるRAGを活用したツールです。部門やプロジェクトごとに社内データを登録することで、一般的な大規模言語モデルとは異なり、要件に最適化された回答を得ることが可能となっています。
【出典】LINEヤフー、RAG技術を活用した独自業務効率化ツール「SeekAI」を全従業員に本格導入。膨大な社内文書データベースから部門ごとに最適な回答を表示し、確認・問い合わせ時間を大幅に削減|LINEヤフー株式会社
【事例2】三井住友銀行
三井住友フィナンシャルグループでは、社内向け汎用型AIアシスタントツール「SMBC-GAI」にRAG技術を活用した社内情報検索機能を導入しています。同行では社内規程や通達、業務マニュアルなど約130万件に及ぶファイルを体系的にインデックス化し、SMBC-GAI上で横断的に検索および参照できる機能を開発しました。これにより、従業員は一つのインターフェースから必要な情報を迅速に取得できるようになり、国内企業におけるRAG技術の活用事例として最大級の規模となっています。
【出典】SMBCグループ独自AI「SMBC-GAI」、130万件の社内文書ファイルを横断検索へ──国内最大級RAG活用の舞台裏 | DX-link(ディークロスリンク)- 三井住友フィナンシャルグループ
RAG導入を成功させるための3つのポイント
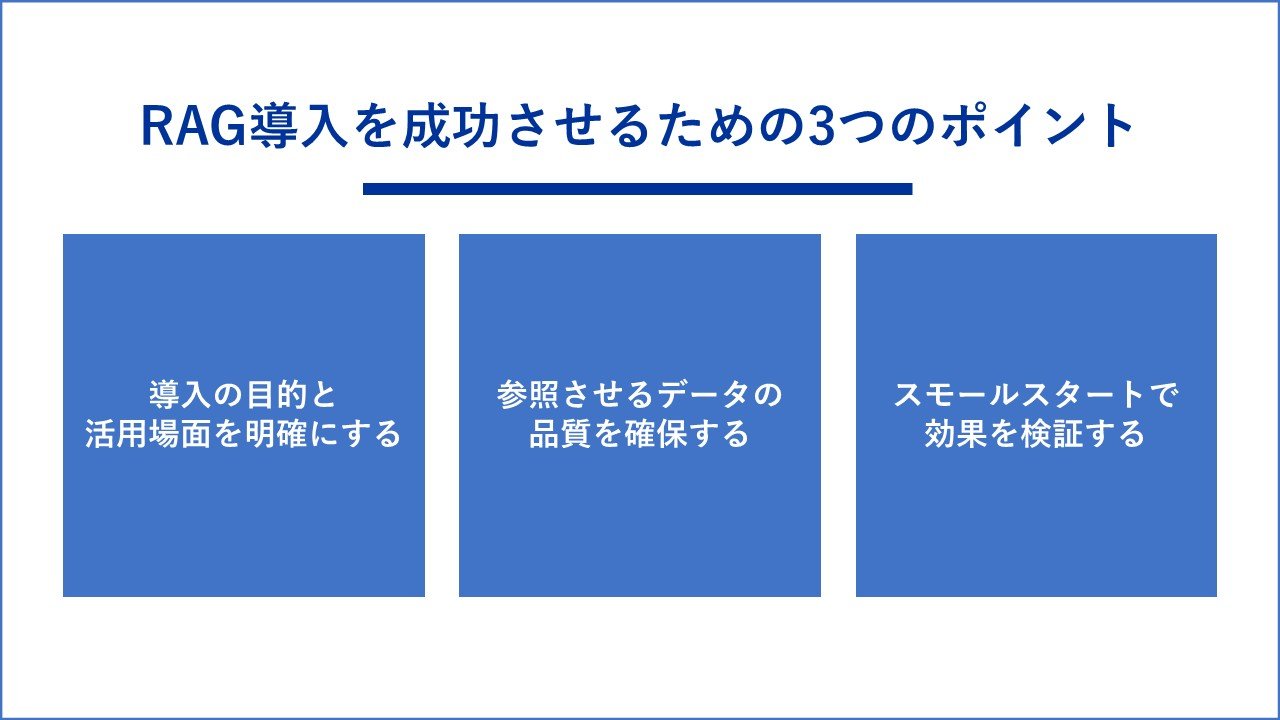
RAGの導入効果を最大化するためには、計画的なアプローチが重要です。特に以下の3つのポイントを押さえることが成功につながります。
【ポイント1】導入の目的と活用場面を明確にする
まず、「誰の、どのような課題を解決するためにRAGを導入するのか」という目的を明確にすることが最も重要です。例えば、「営業担当者が外出先で製品仕様をすぐに確認できるようにする」「新入社員が社内規定について質問しやすくする」など、具体的な利用シーンを想定することで、必要なデータやシステムの要件が定まります。
【ポイント2】参照させるデータの品質を確保する
RAGの回答品質は、参照させるデータの品質に直結します。導入前には、対象となるドキュメントやデータから、古い情報や重複、誤記などを整理・クレンジングしておく必要があります。また、導入後も継続的に情報を最新化し、品質を維持管理する運用ルールを定めておくことが不可欠です。
【ポイント3】スモールスタートで効果を検証する
最初から全社的な大規模導入を目指すのではなく、まずは特定の部門や業務に限定してRAGを導入し、その効果を測定する「スモールスタート」が推奨されます。小さな成功体験を積み重ね、利用者のフィードバックを得ながら改善していくことで、失敗のリスクを抑えつつ、自社に最適な活用方法を見つけ出すことができます。
まとめ
本記事では、生成AIの精度を向上させる技術「RAG」について、その仕組みからメリット、活用事例までを解説しました。
RAGは、生成AIが持つハルシネーションや情報の古さといった課題を克服し、ビジネス活用の可能性を大きく広げる技術です。自社の情報資産と組み合わせることで、業務効率化や顧客満足度向上に貢献する強力なツールとなり得ます。この記事を参考に、RAGの導入を検討してみてはいかがでしょうか。
社内データを活用した「ナレッジ検索(RAG)」を手軽に導入したい企業様へ。AGSの「AI-Zanmai」は、ユーザー数無制限かつ固定料金制のため、全社的な利用に最適です。入力データは学習に利用されないため、セキュリティ面でも安心して業務にご活用いただけます。1カ月の無料トライアルも実施中ですので、詳細は以下のリンクからご確認ください。







